x = ["apple", "banana"]
y = ["apple", "banana"]
z = x
print(x is z) # True (z는 x를 가리킴)
print(x is y) # False (x와 y는 내용은 같지만, 다른 객체)
print(x == y) # True (x와 y는 값이 동일함)
print(x is not y) # True (x와 y는 다른 객체)
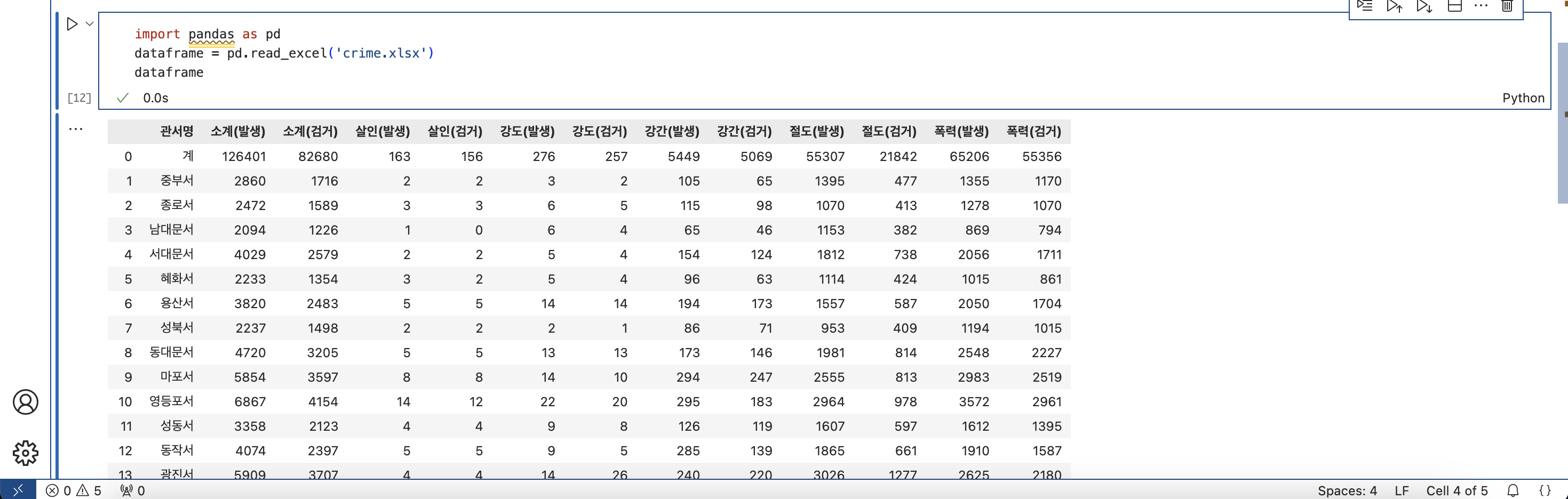
for crime in ['강간', '강도', '살인', '절도', '폭력']:
pvt2[f'{crime} 검거율'] = pvt2[f'{crime}(발생)'] / pvt2[f'{crime}(검거)'] * 100
이렇게 해서 넣어주었어요 (파일 이름 : pvt2)
crime이라는 이름의 리스트를 만들어주었구요
f{} 이렇게 써서 편하게 쓸 수 있어요!
이걸 포매팅이라고 하거든요! 종류가 다양한데,
포매팅은 내일 공부할 겁니다 😎
결과물 아 ~ 주 예뻐서 맘에 들어용 ㅎㅎㅎ
오후 ( 14 : 00 ~ 18 : 00 )
정신없이 찾아보고 물어보고
팀원 분들이랑 소통도 하니까 점심 시간이더라구요
그래서 후다닥 밥 챙겨 먹고,
매니저 님께 git hub 꿀팁 얘기도 듣고 난 후에
남은 문제들 풀어보았습니다!
<Quiz 6_필요없는 column을 del을 써서 삭제하기>
삭제 해봅시다 😎
# Quiz 6_del 사용해서 필요없는 컬럼 삭제하기
for delete_columns in ['강간(검거)','강도(검거)','살인(검거)','절도(검거)','폭력(검거)','소계(발생)','소계(검거)']:
if delete_columns in pvt2:
del pvt2[f'{delete_columns}']
print(pvt2)
앞서 컬럼을 한 번에 생성했듯이
삭제도 같은 방식으로 해보았어요
되네요..?
됐다고 나오니까 오히려 불안했어요,, 👀
그래서 확인 받으러 튜터 님께 갔죠?
# Quiz 6_del 사용해서 필요없는 컬럼 삭제하기
for delete_columns in ['강간(검거)','강도(검거)','살인(검거)','절도(검거)','폭력(검거)','소계(발생)','소계(검거)']:
if delete_columns in pvt2:
del pvt2[delete_columns]
print(pvt2)
word = "Python"
print(f"단어 '{word}'의 길이는 {len(word)}입니다.")
함수 len()이 들어가서도 작동이 가능해요!
대신 {len()} 구조로 들어가야 하네요!
단어 'Python'의 길이는 6입니다.
6. 할당하기 (=)
x = "배"
y = "민경"
print(f"{x=}, {y=}") # 변수명과 값 출력
오,, ㅋㅋㅋㅋㅋㅋㅋㅋ
재밌네요! 되게 유용하네요
다양하게 많이 쓰이니까, 신기한 거 같아요
한 번 더 파일명을 언급하지 않아도 된다는 것도 너무 좋구요!
<Quiz 7_ rename>
드디어 마지막 문제입니다!!
rename을 해볼게요!
이번에도 for문으로 해결할 겁니다!
# Quiz 7. rename하기
# 1트
for rename_columns in {'강간(발생)':'강간','강도(발생)':'강도','살인(발생)':'살인','절도(발생)':'절도','폭력(발생)':'폭력'}:
if rename_columns in pvt2:
pvt2.rename(rename_columns)
될 줄 알았는데 안 되더라구요
# 오류 내용
TypeError: Index(...) must be called with a collection of some kind, '강간(발생)' was passed