인사말
안녕하세요~!
오늘이 역대급으로 추운 날이래요! 다들 감기 조심하세요!
운전 조심하시구요!
오늘도 파이팅입니다~!
| 오늘의 일정 | |
| 오전(09:00 ~ 13:00) | 09:00~10:00 코드카타 및 팀 오전 회의 10:00~10:30 개인 과제 발제 11:30~13:00 베이직반 수업 |
| 오후(14:00 ~ 18:00) | 14:00~16:10 Git 특강 16:10~17:00 Git(브랜치, merge) 다시 해보기 17:00~18:00 TIL 작성 |
| 저녁(19:30 ~ 21:00) | 19:00~21:00 프로그래머스 4문제 |
요약
- 코드 카타 3문제(09:00~10:00)
- 문자열 안에 문자열
- 특정 문자 제거하기
- 아이스 아메리카노
- 개인 과제 발제(10:00~10:30)
- 베이지반 수업(11:30~13:00)
- 조건문 쓸 때 주의할 점
- 조건 표현식 (Conditional Exprossion) == 삼항 연산자(Ternary Operator)
- enumerate() 함수
- pass
- Git 특강 (14:00~16:10)
- 명령어 복습
- 브랜치
- Merge
- 프로그래머스 4문제 풀이(19:00~21:00)
- 개미 군단
- 가위 바위 보
- 숨어있는 숫자의 덧셈(1)
- 대문자와 소문자
오전(09:00 ~ 13:00)
1. 코트 카타
1.1. 문자열 안에 문자열

def solution(str1, str2):
if str2 in str1:
answer = 1
else:
answer = 2
return answer
🤔 문제 풀이
- if str2 in str1: answer = 1
- 만약에 str1 안에 str2가 있다면 1로 출력해 주세요
- else: answer = 2
- 그게 아니라면 2를 출력할게요
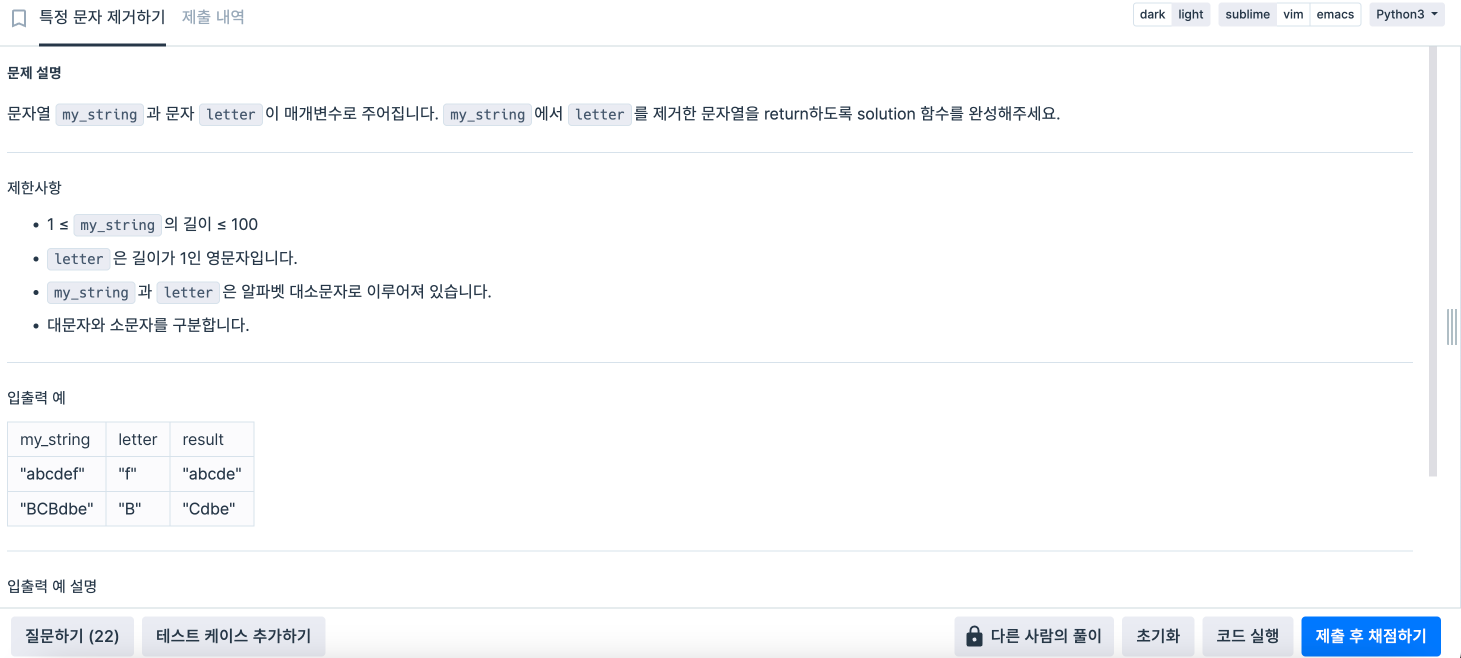
1.2. 특정 문자 제거하기

def solution(my_string, letter):
answer = ''
for i in my_string:
answer = my_string.replace(letter, '')
return answer
🤔 문제 풀이방법
- my_string에서 letter를 지울 거예요
- for i in my_string: answer = my_string.replace(letter, '')
- my_string을 순차적으로 순회할게요
- .replace() 함수를 써서 letter를 공백으로 바꿔줬어요
다른 사람 풀이
def solution(my_string, letter):
str_l = list(my_string)
while letter in str_l :
str_l.remove(letter)
answer = ''.join(str_l)
return answer
🤔 문제 풀이방법
- my_string을 list로 변환하여 str_l로 저장
- str_l에 letter가 있는 동안 반복해서 실행
- remover() 함수를 사용하여 str_l에서 letter을 지워준다.
- join() 함수를 사용하여 srt_l을 다 붙여주기!
💬
join이라는 함수가 보이더라구요 신기했어요
저게 어떤 식으로 출력되는 건지 궁금해서 VSCode로 돌려봤어요

def solution(my_string, letter):
str_l = list(my_string)
while letter in str_l :
str_l.remove(letter)
answer = ''.join(str_l)
return answer
a = solution("abcdef","f")
print(a)
와,, 진짜 신기해요 ㅋㅋㅋㅋㅋㅋ
표현법이 다양한 세계라 그런지 신기하네요
하나 더 배워갔어요 ㅎㅎ
1.3. 아이스 아메리카노

def solution(money):
answer = []
coffee = money % 5500
if coffee == 0:
answer = [money // 5500, 0]
else:
answer = [money // 5500, money % 5500]
return answer
🤔 문제 풀이방법
- answer = []
- 최대로 마실 수 있는 커피 잔 수와, 거스름돈을 담을 리스트를 만들어줄게요
- coffee = money % 5500
- 커피의 잔 수는 money%5500입니다
- if coffee == 0: answer = [money // 5500, 0]
- 만약에 coffee가 나머지가 없는 경우, money//5500을 해줄게요. 그리고 거스름돈은 0원입니다
- else: answer = [money // 5500, money % 5500]
- 다른 경우는 coffee가 나머지가 있는 경우겠죠
- 커피의 잔은 몫으로 구해주고, 잔 돈은 나머지로 구해주면 끝입니다
다른 사람 풀이
def solution(money) :
return [money//5500, money%5500]
이렇게 간단하게 표현할 수 있다는 거,, 배워갑니다 핳ㅎ
(10:00~10:30)
2. 개인 과제 발제
개인과제가 머신러닝 관련해서 발제되었어요 😞
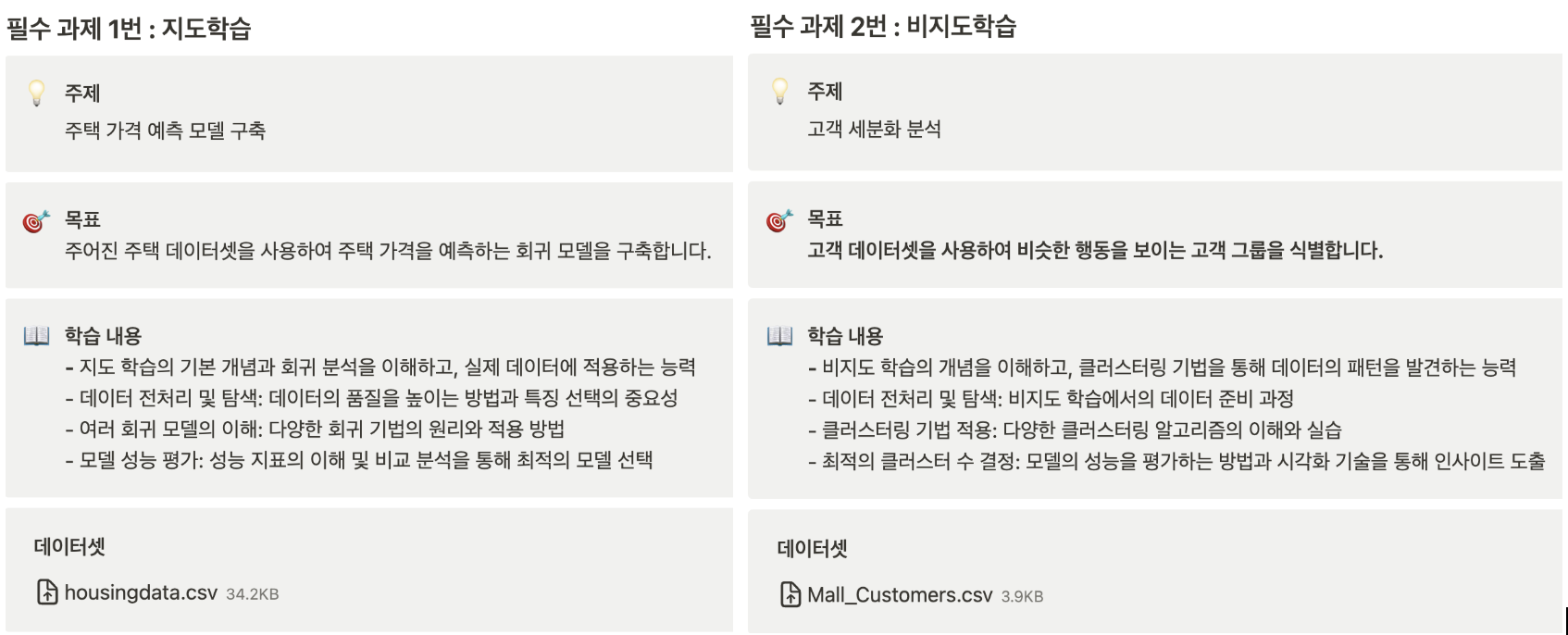
머신러닝의 지도학습과 비지도학습에 대한 과제를 받았어요
12월 31일까지 마감이네요
잡생각 가지지 말고 그냥 해보려구요
(11:30~12:30)
3. 베이직반 수업
3.1. 조건문 쓸 때 주의할 점
- 문자열은 ""일 때 false값을 출력함 (공백은 비어있다고 판별하지 않음)
- 정수형 0이 false값
- 빈 리스트일 때 false
- 리스트, 딕셔너리, 튜플 == 컨테이너 타입
3.2. 조건 표현식 (Conditional Exprossion) == 삼항 연산자(Ternary Operator)
- 개념 : if문을 줄 바꿈을 쓰지 않고 한 줄로 쓰는 것
- 예
age = 22
display_str = ""
if age >= 19:
display_str = "어른이군요"
else:
display_str = "어린이군요"display_str = "어른이군요" if age >= 19 else "어린이군요"
print(display_str)
3.3. enumerate() 함수
for number, name in enumerate(name_list):
print(f"{number}번 {name}님")
3.4. pass
- 개념 : 추후, 코드를 다시 쓸 때를 표시함
- 특징
- 오류 뜨지 않도록 하려고 씀
- 구성 맞춰놓는 공기 같은 존재
- 예

if문을 아직 완성시키지 않은 상태잖아요
그럼 당연히!! 오류가 나죠

하지만, pass를 적어준다면 오류가 발생하지 않습니다
나중에 다시 찾아와서 조건문을 완성시켜 주면 되겠죠? 🤭
오후(14:00 ~ 18:00)
베이직반 수업이 끝나니까 점심시간이 되었더라구요!
다들 식사 맛있게 하셨나용?
오후에는 Git 특강이 있어서 들은 후에 다시 직접 해보면서 시간을 보냈어요!
(14:00~16:10)
4. Git 특강
4.1. 명령어 복습
| local 명령어 | 설명 | remote 명령어 | 설명 |
| git init | 현재 폴더를 깃으로 관리하겠다 | git remote add origin {url} | 원격 저장소에 repo 추가하기 |
| git status | 깃 상태 확인 | git push {origin master/main} | git hub에 넣기 |
| git add | 깃을 SA에 추가 (staging area) |
git clone {repo_url} | repo를 local에 연결하기 |
| git commit -m "" | 커맨드 메시지 남기기 | git pull origin master/main | repo에서 local로 파일 받아오기 |
| git log | 깃 전적 검색 |
| 명령어 | 설명 |
| .gitignore | 깃 허브에 올릴 시, 표시하지 않고 싶을 때 씀 (폴더, 파일 모두 가능) |
4.2. 브랜치
| 명령어 | 설명 |
| git switch -c {branch_name} | 브랜치 생성 또는 이동 |
| git switch {branch_name} | 해당 브랜치로 이동 |
4.3. Merge
| 명령어 | 설명 |
| git merge {branch_name} | 브랜치를 합치는 명령어 |
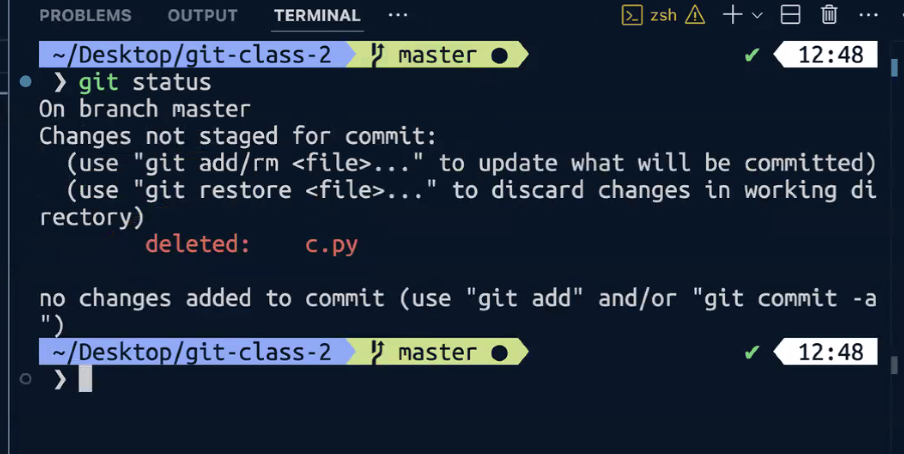
강의가 끝난 후 직접 git hub에서 해보았어요

너~무 어렵고 너~무 재밌어요
물론 튜터님과 함께 해서 했지만요,, ㅋㅋㅋㅋㅋㅋㅋㅋ
그래도!
"~~ 하세요!"라고 하시면 제가 명령어를 적긴 적었어요!!
저번주 주말에 git 명령어 복습을 해보길 잘한 거 같네요 ㅎㅎ
저녁(19:00 ~ 21:00)
5. 프로그래머스 4문제
5.1. 개미 군단
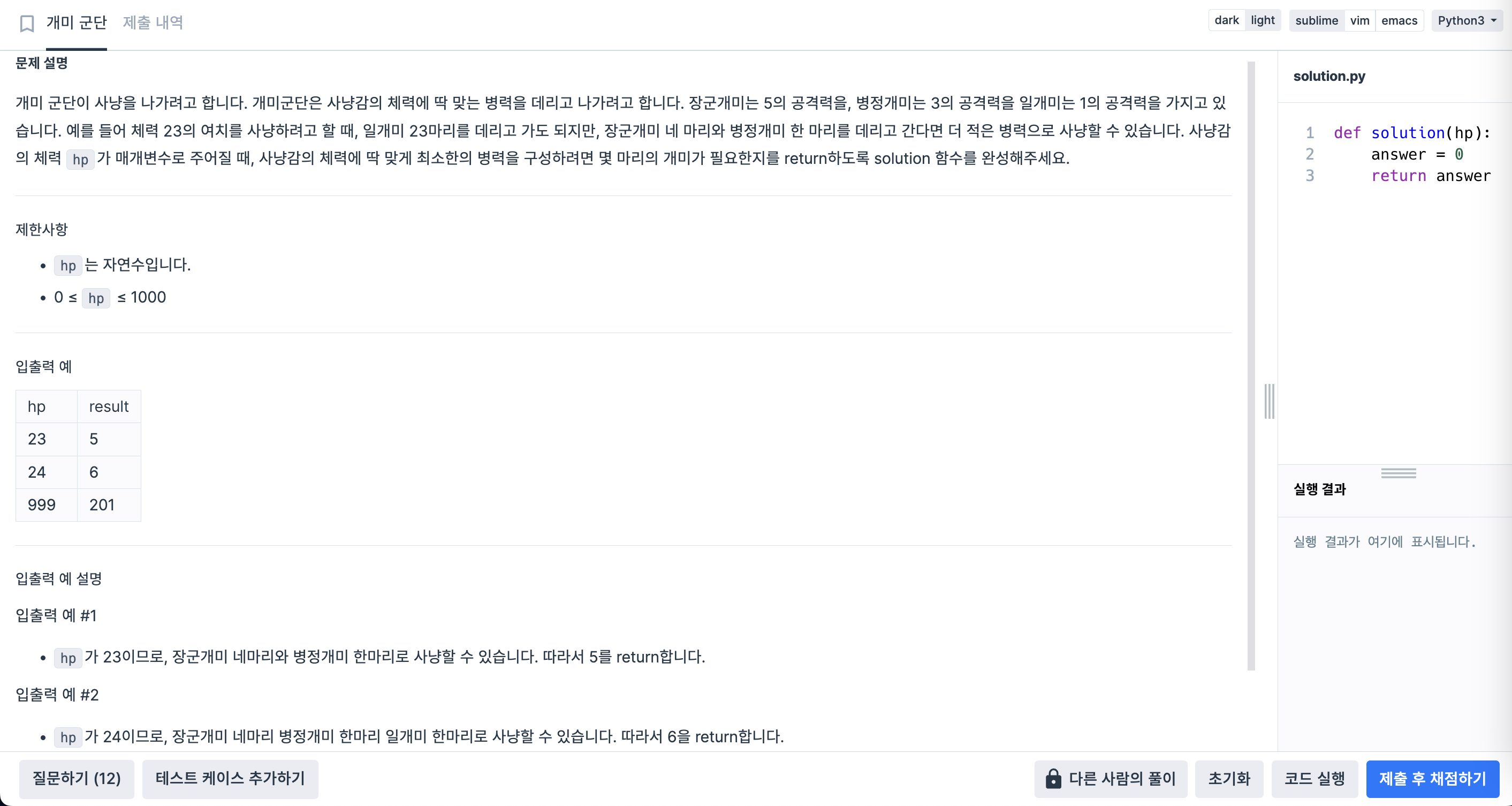
def solution(hp):
general_ant_count = hp//5
soldier_ant_count = (hp - (5*general_ant_count))//3
worker_ant_count = (hp - (5*general_ant_count) - (3*soldier_ant_count))//1
answer = general_ant_count + soldier_ant_count + worker_ant_count
return answer
🤔 문제 풀이
- hp가 주어지고, 최소한의 개미 수를 통해서 사냥을 갈 겁니다!
- 장군개미는 5의 공격력, 병정개미는 3의 공격력, 일개미는 1의 공격력이에요
🧐 코드 풀이
- general_ant_count = hp//5
- 먼저 장군개미만 출격하는 경우를 몫으로 구해줬어요
- soldier_ant_count = (hp - (5*general_ant_count))//3
- soldier_ant_count =
- 두 번째로는 병정개미만 출격하는 경우는
- (hp - (5*general_ant_count))
- hp에서 (장군개미가 출격한 몫에 곱하기 5의 공격력을 해준 값에 뺀 후의 값에
- //3
- 병정개미의 공격력을 몫으로 나눠줬어요. 그럼 병정개미의 수가 나오겠죠!?
- soldier_ant_count =
- worker_ant_count = (hp - (5*general_ant_count) - (3*soldier_ant_count))//1
- 병정개미의 수를 구할 때와 비슷한 구조로 흘러갑니다!
- 대신 이번에는 hp에 장군개미 수와 병정개미 수를 빼주어야겠죠!
- answer = general_ant_count + soldier_ant_count + worker_ant_count
- 그 뒤 총 출격하는 개미의 수를 더해주면 문제는 풀립니다!
5.2. 세균 증식

def solution(n, t):
return n*(2**t)어떤 세균은 1시간에 두 배로 증식한다고 합니다.
🤔 문제 풀이
- 처음 주어진 세균 수가 n이죠 여기에 시간(t)이 지날수록 2배로 늘어난다 했으니까 제곱근!으로 해준 뒤 처음 세균 수에 곱해줍니다
- 그러면 문제가 해결된답니다 🥳
5.3. 가위 바위 보

def solution(rsp):
answer = ''
for i in rsp:
if i == '2':
answer += '0'
elif i == '0':
answer += '5'
else:
answer += '2'
return answer가위 == 2
바위 == 0
보 == 5
🤔 문제 풀이
- 문제를 보자마자 for문으로 돌려줬어요
- 문자열로 나타내라 했으니까 for문 안에는 모두 ''을 달아줄게요
- for i in rsp:
if i == '2':
answer += '0'- rsp 속 문자열을 하나하나 i에 받았어요
- 만약 i가 '2'라면 '가위'죠?
- answer은 '보'인 '0'이 나오면 이기겠죠! 그걸 answer에 바로 넣어줄게요(+=)
- elif i == '0':
answer += '5'- 다음으로 i가 '바위'인 '0'이라면
- answer은 '보'인 '5'가 나오게끔 설정하고 answer에 바로 넣어줄게요(+=)
- else:
answer += '2'- 남은 경우는 i가 '보'인 경우밖에 없어요
- 그렇기에 answer에는 '가위'인 '2'만 추가해 주면 문제 해결!
5.4. 숨어있는 숫자의 덧셈(1)

def solution(my_string):
answer = 0
number = ['0','1','2','3','4','5','6','7','8','9']
for i in range(len(my_string)):
if my_string[i] in number:
answer +=int(my_string[i])
return answer
🤔 문제 풀이
- number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
- 주어지는 my_string에서 숫자만 뽑아내기 위해서 숫자 리스트를 만들어주었어요
- for i in range(len(my_string)):
if my_string[i] in number:
answer +=int(my_string[i])- for문으로 range() 함수를 돌려줄 거예요. 얼마큼요? my_string의 len(길이) 만큼요!
- range() 함수는 변숫값만큼 범위를 주는 함수죠!
- 만약 my_string[i] 값 중에서 number 리스트에 있는 숫자라면
- answer은 int(my_string[i]) 한 걸 바로 더하면서 출력해 줄게요(+=)
- 그러면 문제 해결! 🥰
- for문으로 range() 함수를 돌려줄 거예요. 얼마큼요? my_string의 len(길이) 만큼요!
마무리

TIL을 꾸준히 쓰고 열심히 했더니 우수자로 뽑혔어요!
너무 뿌듯하고 자랑스러웠어요
오늘 강의들도 다 너무 재미있었고, 머리에 새로운 지식들이 들어와서 그런지 기분 좋은 하루였어요 😋
게다가 프로그래머스도 문제가 잘 풀려가지고 빠른 시간에 해결했답니다! 😋
이제 개인 과제인 머신러닝만 잘하면 될 거 같아요!
파이팅!!
모두들 오늘 하루도 수고 많으셨습니다
감기 조심하시고, 푹 쉬세요! 🥳
'내일배움캠프 TIL' 카테고리의 다른 글
| 내일배움캠프 본캠프 17일차_코드 카타, 백준, 머신러닝 특강 (0) | 2024.12.17 |
|---|---|
| 내일배움캠프 본캠프 16일차_프로그래머스, 특강 3개 (1) | 2024.12.16 |
| 내일배움캠프 본캠프 15일차_ 코드 카타, git 특강 (0) | 2024.12.13 |
| 내일배움캠프 본캠프 14일차_코드 카타, 프로그래머스 7일차 (2) | 2024.12.13 |
| 내일배움캠프 본캠프 13일차_코드 카타 3문제, git, 머신러닝 전처리, 프로그래머스 6일차 문제 (6) | 2024.12.11 |