인사말
안녕하세요! 오늘은 화요일입니다!
솔직히 평일이 천천히 갔으면 좋겠어요
공부해야 할 것도 많고,
풀어야 할 문제도 많기 때문에
곁에서 물어볼 사람이 항상 있는, 평일이 좋아요
천천히 흘러갔으면 좋겠습니다 😢
일단은 오늘도 파이팅입니다!
| 오늘의 일정 | |
| 오전(09:00 ~ 13:00) | 09:00 ~ 11:20 코드카타 2문제, 팀 회의, 프로그래머스 1문제, 다른 분들과 피자 나누기(2) 코드 리뷰 11:20 ~ 13:00 머신러닝 이상치 값 처리 실습 |
| 오후(14:00 ~ 18:00) | 14:00 ~ 15:45 통계학 실시간 특강 시청 15:45 ~ 17:10 프로그래머스 5일차 3문제 풀기 17:20 ~ 17:35 저녁 순회 맞이 17:40 ~ 18:00 TIL 정리 |
| 저녁(19:30 ~ 21:00) | 19:30 ~ 21:00 백준 문제 풀기 |
요약
- 코드카타
- 숫자 비교하기
- 나머지 구하기
- 프로그래머스_옷가게 할인받기
- 머신러닝 이상치 값 처리
- IQR 방법
- 이상치 제거
- 중복값 제거
- 통계학 특강 시청
- 벡터의 내적
- 유사성 확인하기 (유클리드, 코사인)
- 고유값 고유벡터
- 최적값 알고리즘
- 텐서
- 프로그래머스 5일 차 3문제
- 아이스 아메리카노
- 나이 출력
- 배열 뒤집기
- 백준 3문제
- AxB
- A/B
- 사칙연산
오전(09 : 00 ~ 13 : 00)
오늘의 코드 카타는 숫자 비교하기와 나머지 구하기였습니다!
수학 연산자와 if문을 다시 확인할 수 있었던 문제였습니다
<숫자 비교하기>

def solution(num1, num2):
if num1 == num2:
answer = 1
elif num1 != num2:
answer = -1
return answer문제를 천천히 따라 적으면
이렇게 코드가 완성됩니다
!=와 ==이 자주 사용되는 거 같은 요즘이네요!
<나머지 구하기>
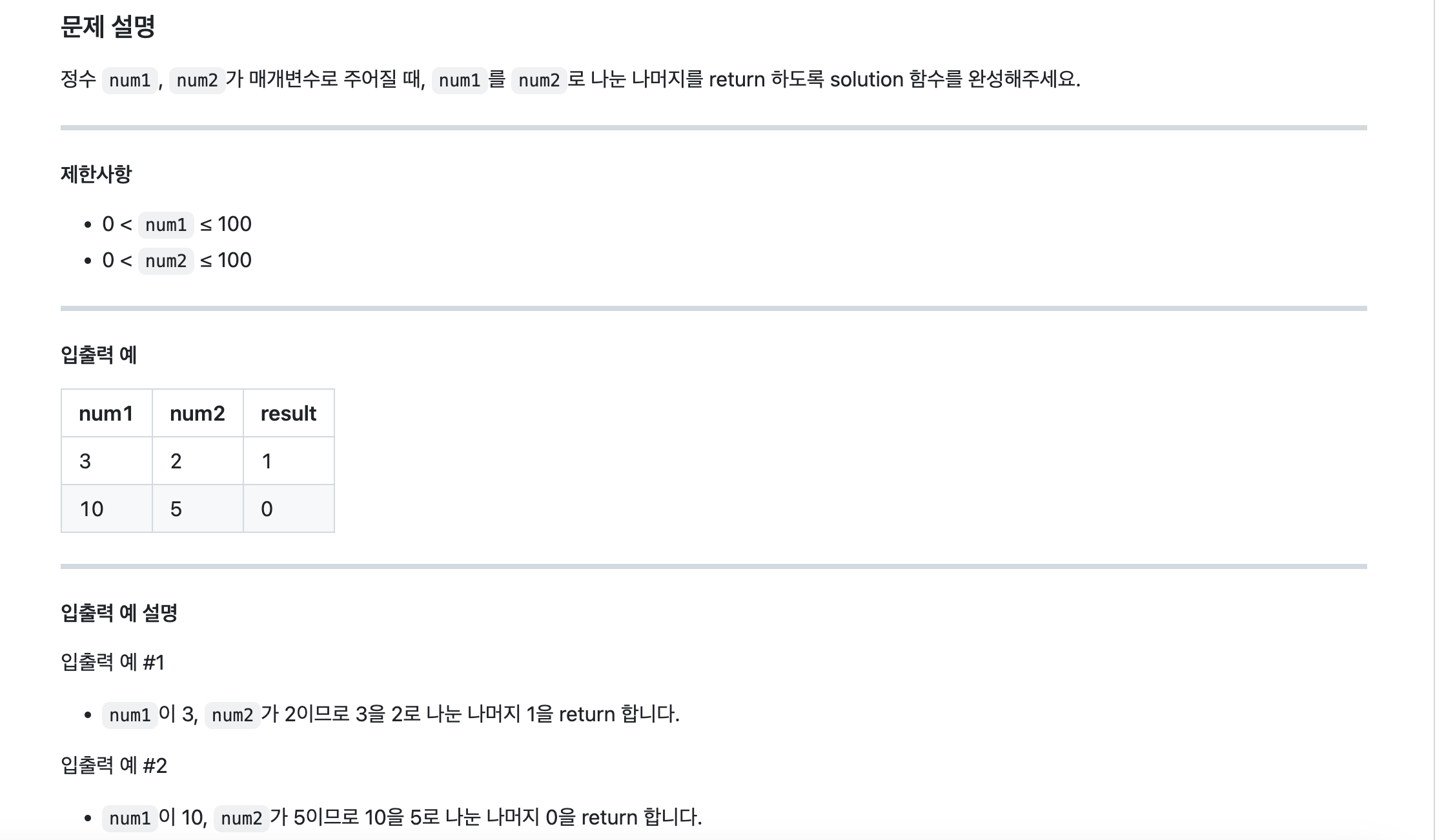
def solution(num1, num2):
answer = num1 % num2
return answer나머지가 나오는 함수인 %를 써서 해결했습니다
| 연산자 | 역할 |
| % | 나머지 |
| / | 나누기 |
| // | 몫 |
이젠 안 까먹을 거 같네요!
코드 카타를 푼 후에 시간이 많이 남아서
오늘 저녁에 풀 예정이었던
프로그래머스 5일 차 4문제 중
한 문제를 풀어보았습니다 😁
<옷가게 할인받기>

import math
def solution(price):
if price >= 500000:
answer = price - price * 0.2
elif price >= 300000:
answer = price - price * 0.1
elif price >= 100000:
answer = price - price * 0.05
else:
answer = price
return int(math.trunc(answer))
def solution(price):
if price >= 500000:
answer = price - price * 0.2
elif price >= 300000:
answer = price - price * 0.1
elif price >= 100000:
answer = price - price * 0.05
else:
answer = price조건에 10만 원, 30만 원, 50만 원 이상 구매 시 각각 할인해 주잖아요!
그래서 할인된 가격으로 if문과 elif문을 완성해주었습니다
else에는 10만 원, 30만 원, 50만 원 이상을 구입하지 않은 경우를 넣었구요!
처음에는
def solution(price):
if price >= 100000:
answer = price - price * 0.05
elif price >= 300000:
answer = price - price * 0.1
elif price >= 500000:
answer = price - price * 0.2
else:
answer = price이 순서로 기입했는데요!
튜터님께서 순서를 바꿔야 할 거 같다고 하셔서
잠시 생각을 해보았습니다
단계별로 조건을 확인하기 때문에
시작값이 작으면 중복 할인이 된다고 생각을 했어요
그래서 50만 원을 시작 조건으로 두었습니다 :)
import math
return int(math.trunc(answer))그리고 소수점 밑으로는 모두 버려야 해서
import math로 .trunc() 함수를 불러왔어요
소수점 이하 숫자는 모두 버리는 함수라고 하더라구요
튜터님께서 알려주셔서 알게 된 함수입니다!
이렇게 문제 3개를 풀고 워밍업을 해주었습니다 😋
재밌네요!

이건 다른 동기분의 풀이예요!
저처럼 가격을 계산하는 게 아니라
discount_rate으로 계산하셨더라구요
이런 방법도 있다는 걸 배웠습니다
코드 공유해 주셔서 감사해요 😽
그리고 함수 공유해주셔서 감사해요!
| 함수 | 설명 |
| import math math.gcd(a,b) |
최대공배수 |
| import math math.lcm(a,b) |
최대공약수 |
(11:20 ~ 13:00)
2. 이상치 값 처리

# 특정 열의 이상치 확인 (IQR 방법)
Q1 = df['C'].quantile(0.25)
Q3 = df['C'].quantile(0.75)
IQR = Q3 - Q1
print(IQR)IQR 방법으로 해볼 거기 때문에
print(IQR)을 해서 값을 확인했습니다
197.0으로 나왔네요!
# 이상치 범위 설정
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
## 이상치 범위 확인
print(lower_bound)
print(upper_bound)그리고 이상치 범위를 확인해 보았습니다

lower가 -292.5고 upper가 495.5네요??
이제 이 범위를 넘어서는 이상치 값을 찾으면 됩니다!
# 이상치 확인
outliers = df[(df['C'] < lower_bound) | (df['C'] > upper_bound)]
print(outliers)
칼럼들 중에서 C를 기준으로 해보았기 때문에
C칼럼 중에서 이상치 값은 14줄에 있던
C 500이라는 결괏값이 나왔어요!
이상치는 이렇게 확인할 수 있다는 걸 알게 되었습니다 😋
2.2 이상치 제거
이제 이상치도 찾았으니까 이상치를 제거해봐야죠😎
# 이상치 제거
df_no_outliers = df[(df['C'] >= lower_bound) & (df['C'] <= upper_bound)]
print(df_no_outliers)
아까 이상치가 있었던 행이 14번째 줄이었잖아요?
말끔히 지워졌습니다 😋
제거를 해주려면 lower와 upper 값 사이에 속하는 값만 출력해 주면 되네요!
2.3 중복값 제거
| 함수 | 설명 |
| .duplicated() | 중복된 행 확인 |
| .drop_duplicates() | 중복된 행 제거 |
# 중복된 행 확인
print(df.duplicated().sum())
이렇게 중복된 행을 확인해 보니까 불리언 형태로 확인되네요!
확인되었으니까 제거해줍시다 😋
8번째 줄이 사라지면 돼요!
# 중복된 행 제거
df_no_duplicates = df.drop_duplicates()
print(df_no_duplicates)
8번째 줄이 사라졌습니다! 두둥!
완전 신기해요 🤩

오전 시간이 이렇게만 했을 뿐인데
벌써 다 흘러가버려서 기분이 이상해요
시간 너무 빨라요 ㅠㅠ
아직 해야 할 것도 많은데,, 천천히 갔으면 좋겠어요 😔
오후(14 : 00 ~ 18 : 00)
오늘도 14시부터 16시까지 통계학 특강을 들었습니다!

3.1 벡터의 내적
: 두 개의 벡터를 곱하고 더해서 하나의 벡터로 표현하는 것

행렬이었던 것을 열행의 순으로 해주는 걸 의미합니다
3.2 유사성 알아보기(유클리드, 코사인)


공간상에서 거리를 통해 유사성을 비교하는 방식입니다

코사인이 0도라는 것은 완전 유사한 값이라는 것을 나타냅니다
코사인이 90도라는 것은 유사하지 않은 값이라는 것을 나타냅니다
3.3 고유값, 고유벡터

고유벡터
: 방향은 변하지 않고 크기만 변하게 해주는 값 (상수배)

ex) 용량을 줄일 때, 기존 틀은 유지해 주고 필요 없는 값만 버릴 때 사용함. 틀은 바뀌지 않아서 고유벡터를 씀
3. 4 최적화 알고리즘

3.5 텐서


(15:45 ~ 18:00) 프로그래머스 문제 풀기
4.1 아이스 아메리카노

처음으로 혼자서 푼 문제였어요
저는 커피를 마시지 않지만,
스스로 혼자 푼 문제 이름이 아이스 아메리카노여서
오래 기억에 남을 거 같아요 ㅠㅠㅠ

잔돈은 나머지로 구하고
커피 개수는 몫으로 구하면 되겠다고 생각했어요
물론 이것도 3트만에 해결한 거랍니다 ㅋㅋㅋ,,,

정답이라고 떴을 때의 그 허탈감은 이루 말할 수 없어요
되겠냐 ㅋ 하고 돌렸는데
됐,, 네?가 됐거든요
얼떨떨해서 기분이 묘했어요 ㅇㅅㅇ,,?

if문으로 문제를 풀고 있지만
다른 분들의 풀이를 한 번씩 보거든요
단순하게 이렇게 했으면 됐던 거였어요,, ㅋㅋㅋㅋ 헤헤
다음에 풀게 될 때!
이 방식을 생각해 내면 되죠 뭐!
어쨌든 혼자 문제를 풀었다는 거에 의의를 두렵니다 🤭
4.2 나이 출력



4.3 배열 뒤집기

생각보다 오래 걸린 문제였어요,,
일단 정렬하는 함수를 .sort()로 알고 있는 상태였지만
거꾸러 하는 방법도 reverse()로 알고는 있었지만
문제 풀 때는 생각이 안 나더라구요 ㅋㅋㅋㅋㅋ

1트는 이렇게 해보았는데 틀렸어요
데헷 - ✨
마지막 너!! 왜 안 되는 건데!!

그래서 팀원 분께 한 번 봐달라고 했습니다
reverse()가 아니라 reversed()로 써야 하고
reversed() 함수를 쓰고나면 다시 list화 해줘야 한대요
그래서 완성한
def solution(num_list):
return list(reversed(num_list))코드였습니다 ㅎㅎ 😜
저녁(19 : 30 ~ 21 : 00)
19:30 ~ 19:50에는 팀 저녁 회의를 진행 해주었어요
5. 백준 문제 풀기
5.1 AxB

a , b = input().split()
a = int(a)
b = int(b)
print(a*b)map함수도 쓸 수 있다 하셨는데,,
저는 아직 .split()가 더 편하더라구요
그래서 이렇게 풀어주었습니다
코드를 편식하면 안 되는 건데, 그쵸? 🤔
이것저것 해봐야겠어요 🤔
5.2 A/B

a, b = map(int, input().split())
print(a / b)그래서
이번에는 map을 바로 적용하였습니다
이렇게 쓰는 거군요! 너무 재밌어요!
5.3 사칙연산

a, b = map(int, input().split())
print(a+b)
print(a-b)
print(a*b)
print(a//b)
print(a%b)단순하게 하나하나 다 입력했습니다
솔직히 while문이나 for문으로 해볼랬다가
다른 분들한테 자문을 구했는데
그냥 프린트로 나열해도 된다 하셔서 해봤어요
너무 쉽게 잘 풀었어요 덕분에!!
마무리
오늘 혼자서 프로그래머스 문제를 풀어봐서 너무 행복했어요!
이제 자력으로도 풀 수 있다는 게 얼마나 감격스러웠는지요 😍
내일도 기대가 되네요!
문제 잘 푸는 제가 되고 싶어요 😘
오늘도 수고 많으셨습니다!
내일도 파이팅!
감사합니다 ☺️
'📕 내일배움캠프 TIL' 카테고리의 다른 글
| [TIL] 내일배움캠프 본캠프 14일차_코드 카타, 프로그래머스 7일차 (2) | 2024.12.13 |
|---|---|
| [TIL] 내일배움캠프 본캠프 13일차_코드 카타 3문제, git, 머신러닝 전처리, 프로그래머스 6일차 문제 (6) | 2024.12.11 |
| [TIL] 내일배움캠프 본캠프 11일차_코드카타 2문제,통계학, 머신러닝 (10) | 2024.12.09 |
| [TIL] 내일배움캠프 본캠프 10일차_머신러닝 전처리 및 백준 3문제,git (0) | 2024.12.06 |
| [TIL] 내일배움캠프 본캠프 9일차_ 머신러닝 (3) | 2024.12.05 |