인사말
오늘 과제 제출을 하고!
내일부터 새로운 강의를 받은 후 공부하기 때문에
이전에 받았던 파이썬 라이브러리 강의를 완강하려 합니다!
그러고 저녁(20 : 00 ~ 21 : 00)엔 Zoom으로 회의가 있고
새로운 과제를 받는다고 하네요 😅
파이팅,,,,
오전 ( 09 : 00 ~ 13 : 00 )

Git Hub에 폴더 생성 완료해주고! ( ~10 : 00)
파이썬 라이브러리 강의를 시청하였습니다.
<10 : 00 ~ 20 : 00>
요약
- Pandas 개념
- 시리즈(Series)
- 데이터프레임(DataFrame)
- 시리즈(Series) vs 데이터프레임(DataFrame)
- Numpy(Numerical Python)
- 연산
- 기타 메서드
- 배열의 인덱싱, 슬라이싱
<Pandas>_데이터 처리가 필요한 모든 분야에서 사용됨
- 개념
- 파이썬에서 데이터를 쉽게 다룰 수 있게 해주는 데이터 분석 라이브러리
- 데이터를 표(테이블) 형식으로 다루기 쉽게 만들어 줌
- 다양한 데이터 조각 기능을 제공함
- 데이터를 정리하고 분석하는 데 아주 강력한 도구임.
- 데이터 프레임(DataFrame)
- 판다스의 핵심 자료 구조임
- 엑셀의 스프레드 시트처럼 행(row)과 열(column)로 구성된 2차원 데이터 구조
- 시리즈(Series)
- 단일 열을 나타내는 1차원 데이터 구조
- 데이터 프레임의 구성 요소 중 하나
- 데이터 프레임(DataFrame)
- 특징 : 판다스를 이용하면 데이터의 필터링, 정렬, 집계 등 다양한 작업을 간단한 코드로 수행 가능함
<시리즈 (Series) >
시리즈(Series)
- 개념 : 인덱스(Index)와 데이터 값(Value)이 쌍으로 구성됨
- 특징
- 인덱스를 통해 데이터에 빠르게 접근할 수 있음
- 데이터 타입은 자동으로 설정되지만, 원하는 타입으로 변경 가능함
- 예시
import pandas as pd
# 시리즈 생성
s = pd.Series([10, 20, 30, 40], index = ['a', 'b', 'c', 'd'])
print(s)a 10
b 20
c 30
d 40
dtype: int64pd.Series()를 쓸 때 시리즈는 꼭 대문자로 작성해주셔야 오류가 안 나요!!
<데이터프레임(DateFrame)>
데이터프레임(DateFrame)
- 개념
- 2차원의 표 형태 데이터 구조
- 엑셀의 전체 시트(Sheet)처럼 생김
- 여러 개의 시리즈(Series)가 모여서 만들어짐.
- 특징
- 행(row)과 열(column)로 구성된 2차원
- 다양한 데이터 타입을 각 열에 담을 수 있음
- 인덱스와 컬럼명을 사용해 특정 데이터에 접근할 수 있음
- 예시
# 예시: 데이터 프레임 생성
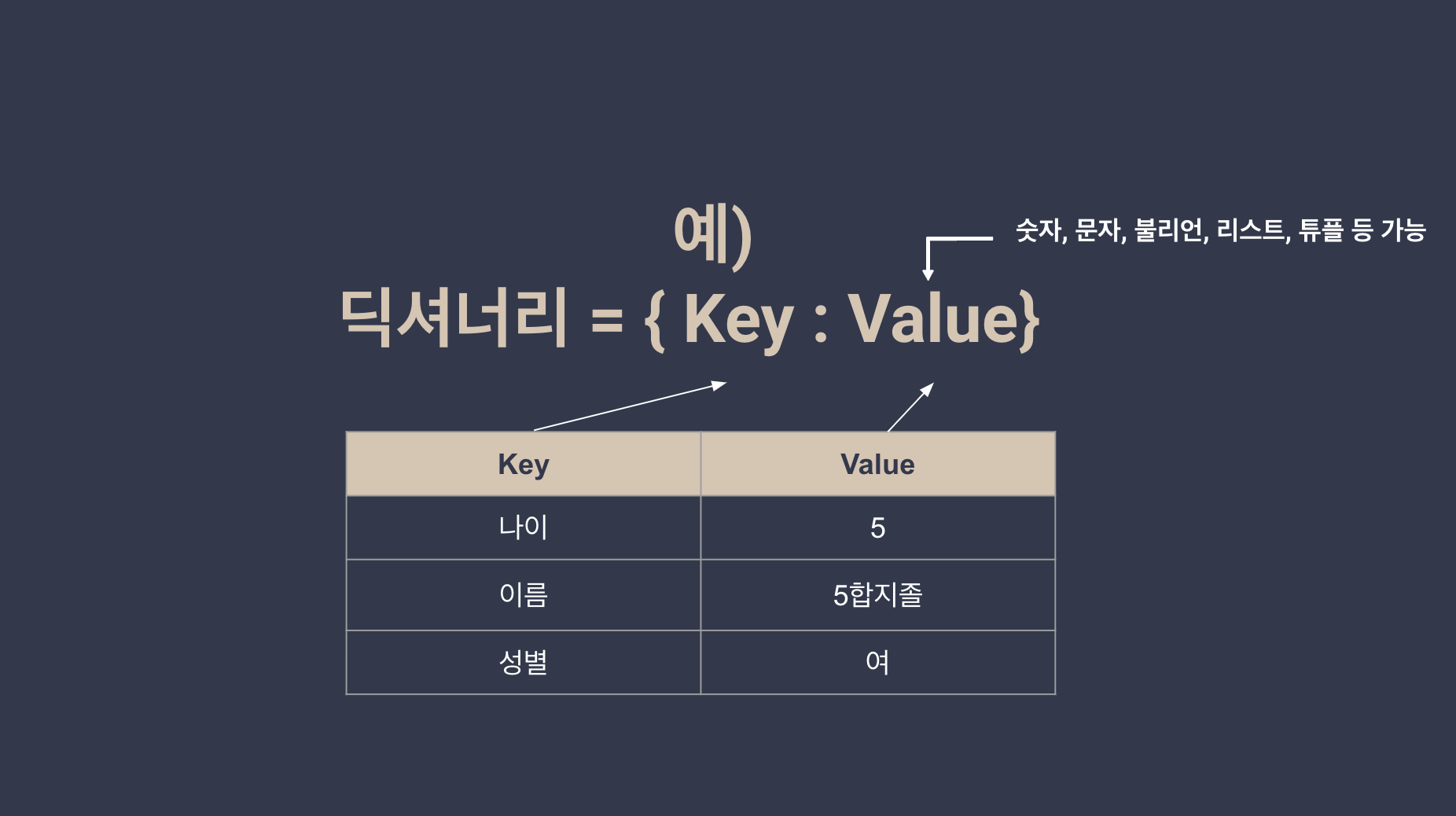
data = {
'이름': ['철수', '영희', '민수'],
'나이': [25, 30, 35],
'직업': ['학생', '회사원', '프리랜서']
}
df = pd.DataFrame(data)
print(df) 이름 나이 직업
0 철수 25 학생
1 영희 30 회사원
2 민수 35 프리랜서# data의 컬럼만 뽑아보기
data["이름"]
결괏값
['철수', '영희', '민수']# 인덱스와 칼럼명을 사용해 특정 데이터에 접근하기
파일명["이름"][0]
결괏값
'철수'
<시리즈(Series) vs 데이터프레임(DataFrame)>
| 차이점 | 공통점 |
| 시리즈는 1차원, 데이터프레임은 2차원 | 둘 다 인덱스를 가지고 있어서 데이터에 쉽게 접근 가능 |
| 시리즈는 하나의 데이터 타입, 데이터 프레임은 다양한 데이터 타입 기입 가능 (리스트, 튜플, 딕셔너리 등등) |
판다스에서 가장 기본적인 구조 |
<Numpy(Numerical Python)>
- 개념
- 과학 계산에 강력한 성능을 제공하는 파이썬 라이브러리
- 다차원 배열 객체인 ndarray와 배열을 효율적으로 처리할 수 있는 다양한 함수들을 제공함.
- 데이터 분석, 머신러닝, 딥러닝에서 기초가 되는 라이브러리
- 판다스와 함께 자주 사용됨
- 특징
- 고속 배열 연산 : C언어로 작성돼 있어, 파이썬 기본 리스트 보다 훨씬 빠른 연산 가능
- 다양한 수학 함수 : 배열 간의 덧셈, 뺄셈, 곱셈 등의 연산을 효율적으로 수행
- 선형대수, 통계함수 : 복잡한 수학 계산도 간단히 처리 가능
- 예시
- 배열(ndarray) 생성하기
import numpy as np
# 리스트로 생성하기
## 1차원 배열 생성
arr = np.array([1, 2, 3, 4, 5])
print(arr)[1 2 3 4 5]
- 배열의 연산
arr = np.array([1, 2, 3, 4, 5])
# 각 원소에 2를 더하기
arr_add = arr + 2
print(arr_add)
# 각 원소에 2를 곱하기
arr_mul = arr * 2
print(arr_mul)[3 4 5 6 7]
[ 2 4 6 8 10]
- 배열간의 연산
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 배열 간 덧셈
arr_sum = arr1 + arr2
print(arr_sum)
# 배열 간 곱셈
arr_mul = arr1 * arr2
print(arr_mul)[5 7 9]
[ 4 10 18]
- 배열의 기타 메서드
| 메서드 설명 | 메서드 | 코드 | 결괏값 |
| 0으로 채워진 배열 | np.zeros() | zero_arr = np.zeros((2, 3)) # 2x3 크기의 배열 print(zero_arr) |
[[0. 0. 0.] [0. 0. 0.]] |
| 1로 채워진 배열 | np.ones() | ones_arr = np.ones((3, 2)) # 3x2 크기의 배열 print(ones_arr) |
[[1. 1.] [1. 1.] [1. 1.]] |
| 특정 값으로 채워진 배열 | np.full() | # 2x2 크기의 7로 채워진 배열 full_arr = np.full((2, 2), 7) print(full_arr) |
[[7 7] [7 7]] |
| 연속적인 값으로 채워진 배열 | np.arange() | # 0부터 9까지의 연속된 값 range_arr = np.arange(10) print(range_arr) |
[0 1 2 3 4 5 6 7 8 9] |
| 메소드 설명 | 메소드 |
| array 속 개수 확인 | arr.size() |
| array의 데이터 타입 확인 | arr.dtype() |
| array의 용량 차지 확인 | arr.nbytes() |
| array의 차원 확인 | arr.ndim() |
| array를 1차원으로 입력하기 | arr.ravel() |
| array의 차원은 바꾸지 않고 평탄화 | arr.flatten() |
| array의 sum | arr.sum(), arr.sum(axis = 1), arr.sum(axisi = 0) *axis = 1는 열, axis = 0은 행 |
- 배열의 인덱싱과 슬라이딩
인덱싱(Indexing)
: 배열의 특정 위치의 값을 가져옴
arr = np.array([10, 20, 30, 40, 50])
# 첫 번째 원소
print(arr[0])
# 마지막 원소
print(arr[-1])10
50
슬라이싱(Slicing)
: 배열의 일부분을 잘라내는 방법
arr = np.array([10, 20, 30, 40, 50])
# 두 번째부터 네 번째 원소까지
sliced_arr = arr[1:4]
print(sliced_arr)[20 30 40]
다차원 배열의 인덱싱과 슬라이싱
: 콤마(,)로 구분해서 함
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 특정 원소 접근 (2행 3열)
print(arr2d[1, 2])
# 슬라이싱 (2행까지, 2열까지)
sliced_arr2d = arr2d[:2, :2]
print(sliced_arr2d)6
[[1 2]
[4 5]]저녁 ( 20 : 00 ~ 21 : 00)
오늘까지 과제였던 걸 리뷰도 하면서,
새로운 과제를 설명 듣는 Zoom 수업에 참여하였습니다
마무리
벌써 내일이면 새로운 강의를 받게 되고
새로운 과제도 시작하고
새로운 팀에서 새로운 팀원과 공부하게 되네요 😢
시간 너무 빠른 거 같아서 서운할 정도입니다
그래도
모든 분들을 한 번씩은 뵈어야
나중에 팀 프로젝트를 진행할 때 유리할 거 같아요
좋게 생각하려구요,, 아쉽지만 🥲
공부할 게 많이 쌓여있어서
스트레스도 쌓이고 있지만
그래도 해야 하는 걸 어떡합니까!
오늘도 수고 많으셨어요 ㅎㅎ
감사합니다.
'내일배움캠프 TIL' 카테고리의 다른 글
| 내일배움캠프 본캠프 10일차_머신러닝 전처리 및 백준 3문제,git (0) | 2024.12.06 |
|---|---|
| 내일배움캠프 본캠프 9일차_ 머신러닝 (3) | 2024.12.05 |
| 내일배움캠프 본캠프 7일차_피벗 테이블, .drop, 컬럼추가, del, f-string, rename, git 폴더 생성 (3) | 2024.12.03 |
| 내일배움캠프 본캠프 6일차_Python 라이브러리로 데이터 분석하기 (9) | 2024.12.02 |
| 내일배움캠프 본캠프 5일차_ 프로그래머스 3문제 풀이와 과제 진행 (1) | 2024.11.29 |