
📘 DRF
더 효율적으로 사용하기
들어가기 전에,,
“섣부른 최적화는 만악의 근원이다”
- 컴퓨터 과학의 거장 ‘도널드 크누스’
그래도 하고 싶다면 아래 두 단계를 따를 것
- 하지 마라.
- 아직 하지 마라. 완전히 명백하게 이해하고 해법을 찾기 전까지는 하지 마라.
확실하게 이해하고 사용하지 않은 단순 성능상의 이익을 위한 최적화는 결국 더욱 큰 문제로 되돌아온다.
지연로딩(Lazy Loading)
- Django의 ORM은 기본적으로 게으르다!
- 우리가 ORM을 작성하면 작성하자마자 SQL로 변환되어 쿼리 되는 것이 아닌, 최대한 쿼리를 미루다가 해당 데이터가 실제로 사용될 때 쿼리를 진행한다. 이것을 지연 로딩(Lazy Loading)이라고 한다.
- 지연로딩은 아래와 같은 장점이 있으며 많은 ORM에서 구현하고 있는 방식이다.
- 불필요한 데이터베이스 쿼리를 방지하여 필요한 데이터만 쿼리 하여 성능을 보장
- 모든 관련된 데이터를 한 번에 로드하지 않고 필요한 경우에만 쿼리 하므로 메모리 사용을 줄임
- 데이터베이스의 부담을 줄임
comments = Comment.objects.all()
for comment in comments:
print(f"{comment.id}의 글제목")
print(f"{comment.article.title}")- 그럼 위 코드에서는 언제 실제로 쿼리가 발생할까?
- comments = Comment.objects.all() → 쿼리 하지 않음 (예약만 해둠)
- for comment in comments: → comments 조회 쿼리 발생
- print(f"{comment.id}의 글제목") → 쿼리하지 않음 (이미 데이터 가지고 왔음)
- print(f"{comment.article.title}") → 해당 comment의 article id 조회 쿼리 발생(N번)
💡 N+1 Problem
위와 같이 관계형 데이터베이스에서 지연로딩을 사용할 경우 관련된 객체를 조회하기 위해 N개의 추가 쿼리가 발생하고 실행되는 문제다. 당연히 데이터베이스에 많은 부하가 걸리고 응답시간이 느려지는 등의 성능 문제를 야기한다.
어떻게 해결할 수 있을까? 🤔
💡 즉시로딩(Eager Loading)
데이터를 로드할 때 필요하다고 판단되는 연관된 데이터 객체들을 한 번에 가져오는 것.
이를 통해 지연로딩에서 발생하는 N+1 문제를 해결할 수 있다.
너무 많은 데이터를 가져오면 오히려 성능 문제를 야기할 수 있다.
- Django에서의 Eager Loading
- select_related
- one-to-many 또는 one-to-one 관계에서 사용 (N+1)
- SQL의 JOIN을 이용해서 관련된 객체들을 한 번에 로드하는 방식
- prefetch_related
- many-to-many 또는 역참조 관계에서 주로 사용
- select_related를 사용하는 관계에서도 동작
- 내부적으로 두 번의 쿼리를 사용해서 동작
- 첫 번째 쿼리는 원래 객체를 조회하며 두 번째 쿼리는 연관된 객체를 가져오는 방식
- many-to-many 또는 역참조 관계에서 주로 사용
- select_related
- 간단하게 이해하려면 ↓
ModelClass.objects.filter(조건절)
.select_related('정방향 참조') # JOIN
.prefetch_related('역방향 참조') # Additional Query- 그런데, 이게 또 우리 의도대로 100% 동작하지는 않는다. 🙄
- Django가 내부적으로 개발자가 준 여러 옵션들이 불필요하다고 생각될 경우 자기 나름대로의 로직대로 Query를 새로 작성한다.
- 하지만 이게 항상 더 효율적이라는 보장은 없다고 할 수 있다.
바로 사용해 보기
1. 정참조 조회해 보기
더보기


# 정참조 조회하기
@api_view(["GET"])
def check_sql(request):
from django.db import connection
comments = Comment.objects.all().select_related("article")
for comment in comments:
print(comment.article.title)
print("-" * 30)
print(connection.queries)
return Response()
.select_related("article")
이 코드 하나만 더 덧붙였을 뿐인데,
확연히 ORM 로딩 길이가 줄어들었어요
2. 역참조 조회해 보기
더보기


# 역참조 조회하기
@api_view(["GET"])
def check_sql(request):
from django.db import connection
articles = Article.objects.all().prefetch_related("comments")
for article in articles:
comments = article.comments.all()
for comment in comments:
print(comment.id)
print("-" * 30)
print(connection.queries)
return Response()
.prefetch_related("comments")
이번에도 이 코드만 덧붙였을 뿐인데
확연히 ORM 로딩 길이가 줄어들었어요
내 로직 편하게 살펴보기
📕 Silk
- 실시간으로 내 요청에 대한 다양한 정보를 볼 수 있는 검사 도구이다.
- 대시보드를 제공하여 개발자로 하여금 편하게 로직을 분석할 수 있게 도와준다.
- 특히 ORM을 통해 Django 내부적으로 사용하는 쿼리를 바로 확인할 수 있다.
- Silk 외에도 다양한 도구가 존재한다.
📕 설치하기
pip install django-silk
📕 settings.py에 등록하기
MIDDLEWARE = [
...
'silk.middleware.SilkyMiddleware',
...
]
INSTALLED_APPS = (
...
"silk",
)📕 api_pjt/url 설정하기
urlpatterns += [path('silk/', include('silk.urls', namespace='silk'))]
📕 migrate
python manage.py migrateSilk 사용해 보기

postman에서 Send를 누를 때마다 계속 업데이트될 거예요
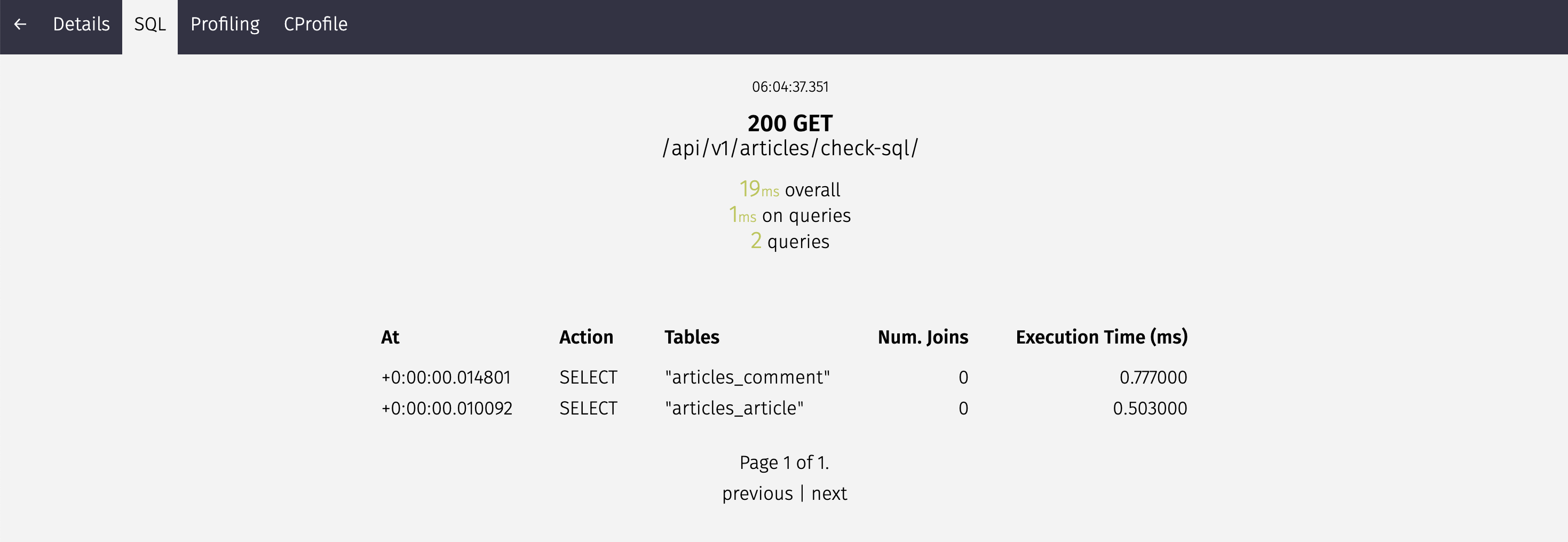
로딩되는 데 몇 초 걸렸는지, 쿼리당 몇 초가 걸렸는지, 몇 개의 쿼리가 발생했는지 알 수 있어요
'공부 > DRF 공부' 카테고리의 다른 글
| [DRF] 더 빠른 속도를 위해, Redis (0) | 2025.02.03 |
|---|---|
| [DRF] Django ORM 한 걸음 더, Q(), F(), annotate(), aggregate() (0) | 2025.02.03 |
| [DRF] Token Auth with JWT, 접근 제한 및 접근하기 (0) | 2025.02.02 |
| [DRF] Serializer 활용하기 (1) | 2025.01.31 |
| [DRF] Relationship과 DRF, 댓글 생성 (0) | 2025.01.30 |